DIY toy taxidermy shop Build-A-Bear had decreed that Thursday, July 12, was Pay Your Age Day in shops across the U.S., Canada, and the U.K. The self-explanatory event lets bear lovers make a furry friend, stuff it with love, and pay a dollar amount that matched their current age—a payment model that vastly favored spoiled 1-year-old knee-biters over 50-year-olds who just needed something to love.
The 21 year old company was likely planning on leveraging nostalgia from grandparents and parents while building loyalty with a new generation of toy-lovers. Now was an especially great time for this campaign as Toys”R”Us has shut down hundreds of stores worldwide and there’s marketshare on the table to capture – especially for a focused, experiential brand like Build-A-Bear.
It was a good plan and a great marketing idea, save for one tiny little problem—the fans loved it too much. In fact, they loved it so much that they started lining up before Build-A-Bear Workshops opened in the U.S. The long lines made the company nervous about crowds and maybe bear riots, so they sent out a statement on social media saying it would limit the number of people who could take advantage of the deal due to safety concerns.
Customers were pissed – especially those who lined up around the block. Plus no one wants to hear you make excuses, blaming “safety concerns” and “local authorities.”
Sadly, all Build-A-Bear had to do was test this genius, goodwill generating campaign at a single store and then in increasingly larger markets to work out the kinks. To make matters worse, Build-A-Bear didn’t jump on the bad press and make anything of it.
Takeaway: Launch slowly – even if you have a great idea – so that any mistakes in your plan or missed assumptions don’t spiral out of control.
It’s Tuesday, March 20, 2018 and today we’re talking about: the Spotify IPO, an IPO Meltdown, and Melting Down Toys”R”Us. Avg read time: 4 min 45 sec. But you’re better than average.
Spotify IPO
Dropbox isn’t the only company about to have its initial public offering. Spotify – the 11 year old music streaming service – is set to IPO in the next few weeks as well. But Spotify is doing things their own way. The Stockholm, Sweden company is doing a direct listing.
This means that Spotify isn’t spending millions to hire an investment bank, isn’t creating new shares to sell, isn’t doing a roadshow to woo potential institutional investors, isn’t setting an offering price, and isn’t selling newly issued shares to institutional investors the night before the IPO so they can then sell those shares on the public market the next day.
On April 3, 2018, current Spotify shareholders will be able to sell their shares directly on the New York Stock Exchange. This Direct Public Offering (DPO) is somewhat rare.
Maybe most importantly, Spotify won’t be raising money with this DPO since they’re not creating new shares and not actually selling any either. Only existing shareholders will be able to sell shares and only they will receive money for those shares. Finally – and this might be the coolest (and riskiest) part – buyers and sellers will have to discover prices without the guidance of an investment bank’s guesstimate. #priceDiscovery!
While both the Dropbox IPO and the Spotify DPO are worth paying attention to, only one is music to my ears. For more information, watch Spotify’s Investor Day for over 2 hours of details.
“Without deviation from the norm, progress is not possible.”
― Frank Zappa
This segment was inspired by The Indicator on March 19, 2018.
IPO Meltdown
Speaking of IPOs, I came across this great HBR story Monday that I’d never heard before about the Facebook IPO in 2012. Apparently the Nasdaq had a crisis while the stock was supposed to be trading live for the first time.
As the start of trading approached, hundreds of thousands of orders poured in. But when 11:05 arrived, nothing happened.
The computer code that was supposed to facilitate the exchange of billions of dollars for the IPO was reporting that something was wrong. Nasdaq managers decided to disable the check that was failing and move forward with the big day.
When the validation check was removed, trading started, but the workaround caused a series of failures. It turned out the check had initially picked up on something important: a bug that caused the system to ignore orders for more than 20 minutes, an eternity on Wall Street. Traders blamed Nasdaq for hundreds of millions of dollars of losses, and the mistake exposed the exchange to litigation, fines, and reputational costs.
The managers screwed up. They pushed forward when they should have stopped.
The Anatomy of a Disaster
A few weeks ago I wrote a long-form piece called The Anatomy of a Disaster where I dissected the worst industrial accident on US soil in 25 years. Nasdaq’s Facebook IPO crisis follows a similar pattern. While I focus more on causes and prevention in my piece, the HBR piece on the Facebook IPO touches more on what to do when you’re already in a disaster. Two great tips they give are:
“Learn to stop. When faced with a surprising event, we often want to push through and keep going. But sticking to a plan in the face of surprising new information can be a recipe for disaster.”
“Do, monitor, diagnose. Sometimes stopping isn’t an option. If we don’t keep going, things will fall apart right away. What can we do then?” If a patient has stopped breathing, start “with a task, such as intubating the patient. The next step is monitoring: you check if performing the task had the expected effect. If it didn’t, then you move onto the next step and come up with a new possible diagnosis. And then you go back to tasks because you need to do something — for example, administer medications or replace the bag — to test your new theory.”
Yesterday I wrote about the Toys”R”Us liquidation. My prototyping, Neuroscientist brother, Tim, pointed out that the phrase category killer is a bit confusing. I wrote back:
Category killer doesn’t mean that a company killed the category.. it means that they dominated (or co-dominated) it due to their focus and scale.
Toys”R”Us was a category killer because they niched down on one thing and one thing only. So while 70 years ago the mom & pop corner stores or Macy’s or Sears may have had a toy section or toy aisle, they didn’t know toys well, their selection was bad, they couldn’t sell toys cheaply, they had no leverage with toy manufacturers, they weren’t known for selling toys, and they didn’t really care about toys to begin with.
There were other toy stores, but they were small operations, making toys in the back, or only able to buy from local toy manufacturers. They were focused but had no efficiency, no scale. There was a huge opportunity for the first chain toy store – a big-box toy store – that could bring together focus, scale, efficiency, and brand.
Toys”R”Us Becomes Category Killer
History.com published a nice piece Monday about the history of Toys”R”Us. Returning from WWII, Charles Lazarus’ intuition told him that America was about to have a lot more babies. After opening a baby furniture store in his father’s bike repair shop, customers started asking for toys. As parents kept returning to buy toys for their growing children, Lazarus got out of the children’s furniture business and went all in on toys.
Big-box stores like Toys ‘R’ Us astonished the era’s consumers, who had simply never seen stores that big and crammed with merchandise. “What Lazarus really captured was this sense of American abundance after the war and after all those years of depression,” says Richard Gottlieb, founder of Global Toy Experts and an authority on the toy business.
From Wikipedia: “At its peak, Toys “R” Us was considered a classic example of a category killer, a business that specializes so thoroughly and efficiently in one sector that it pushes out competition from both smaller specialty stores and larger general retailers.”
Sadly, after Lazarus retired, Toys”R”Us began to lose it’s way. In 2005, Bain Capital, KKR, and Vornado Realty Trust announced a leveraged buyout (LBO). And as is typical for these types of private equity plays, the cost cutting began.
But as Toys ‘R’ Us dialed back its offerings, it cut back on the magic, too. When Toys ‘R’ Us changed its focus from the toys themselves to undercutting the competition, “You didn’t get the elation anymore,” says Gottlieb. “They failed because they ceased to love toys.”
Had Toys”R”Us remained focused on their core values and competency, I think they could have adapted and weathered the back-to-back storms of Walmart (the biggest big-box store) and Amazon.
Hydrogen Sulfide doesn’t have much to do with strategy but I thought I’d publish this mini-post as Patron-only bonus content anyway since it didn’t make it into my piece on disasters:
Hydrogen Sulfide (H2S) is a funny substance. Not only is it extremely flammable, but it’s also very toxic to humans. Fortunately, it has the very distinct smell of rotten eggs – an early warning sign – above 0.5 parts per billion. Unfortunately, at higher concentrations that smell vanishes after only 2 or 3 sniffs as the nerves in your nose become paralyzed.
The maximum recommended concentration is only 20 ppm. But as the concentration of H2S increases to about 1000 parts per million, one breath will instantly cause you to pass out, collapse, and stop breathing. H2S binds to the enzymes that allow your cells to convert sugar and oxygen into energy – energy your body needs constantly.
H2S has one last nasty property: it’s heavier than air, meaning that H2S hugs the ground and dissipates more slowly than other gases. So what typically happens is that you’re wondering around the refinery, smell rotten eggs, pass out, collapse on the ground, and inhale even higher concentrations of H2S until you stop breathing and die.
Hmm.. maybe there is a strategy lesson here. Hydrogen Sulfide is one of those substances that’s almost too deadly to handle. At my refinery we didn’t handle it much. In fact, we paid another company who had deep expertise in H2S to build an H2S processing plant inside of our refinery. They turned H2S into pure sulfur (S) and water.
Are there parts of your business or life – like hydrogen sulfide – that are too deadly to handle? Can you pass off the risk to someone else? Can you eliminate them altogether? Or can you specialize in handling the most toxic or deadly parts of someone else’s business?
PS: Pure sulfur is pretty flammable too… and you haven’t lived until you’ve seen a sulfur pit fire. As the burning sulfur heats up, it melts, turning blood red while the flame itself it blue…
If you listen carefully, you can hear the respirator that the person who’s recording the video is using in order to avoid inhaling the toxic by-products of burning sulfur.
When I first started working at the nation’s largest refinery my boss didn’t have any great projects ready for me so he sent me to “Shift Super” training. There were only 4 of us students – me and 3 unit operators, each with at least 20 years of experience. I was only 19 years old and I barely knew anything about anything.
Each shift supervisor runs a big chunk of the refinery: 2-4 major units. But shift supers needed to know how to supervise any of the 10 or so control centers safely, so on my first day of work I was learning how the entire refinery operated. It felt like a lifetime’s education crammed into 5 days.
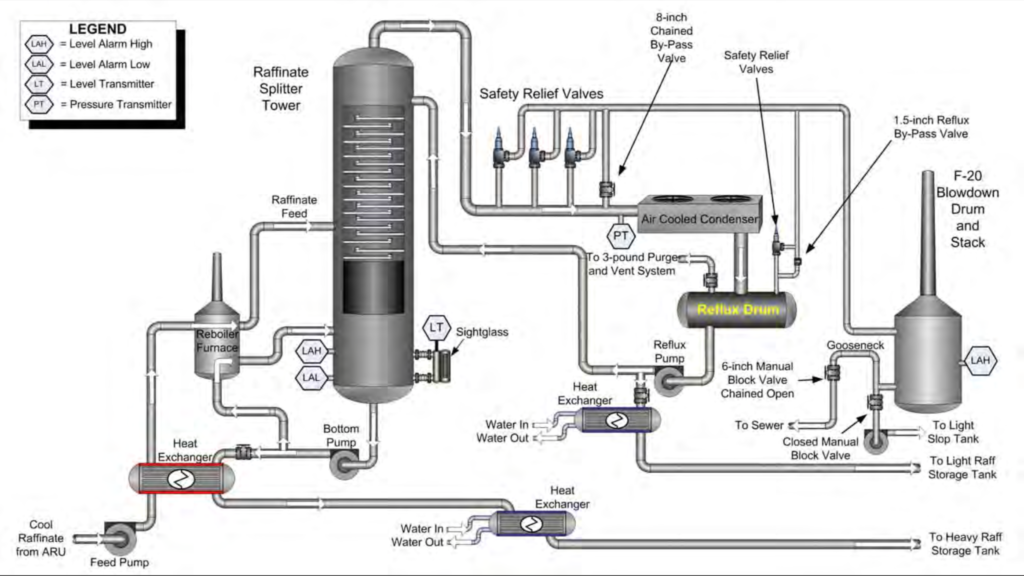
After Shift Super training, I began to see more and more of the refinery with my own eyes. What had been a precise line drawn from one perfect cylinder to another perfect cylinder was actually a rust covered 6-inch pipe baking in the Texas heat transporting high-octane, extremely flammable raffinate from a 170 ft separation tower to a temporary holding tank.
Fear of Disaster
One evening – about 2 weeks in – as the refinery was becoming a real place to me, I had this moment of pure panic while driving home.
With so many things that could go wrong at any moment, how was the refinery still standing? How had it even made it until now? Any minor mistake – in the design, production, construction, or operation of any pipe or vessel – could result in a huge disaster. Would the refinery even be there when I returned tomorrow morning?
I couldn’t sleep. The next morning the refinery was still there. And the next. And the next. And my fears slowly morphed into amazement. My refinery was the largest, most complicated system I had ever attempted to wrap my brain around.
BP Texas City Refinery Explosion
But just 29 miles away from my refinery, investigators were trying to piece together what happened during the nation’s worst industrial disaster in nearly 2 decades.
Fifteen people had been killed and 180 injured – dozens were very seriously injured. The cause of each fatality was the same: blunt force trauma.
Windows on houses and businesses were shattered three-quarters of a mile away and 43,000 people were asked to remain indoors while fires burned for hours. 200,000 square feet of the refinery was scorched. Units, tanks, pipes were destroyed and the total financial loss was over $1.5 billion.
The BP Texas City Refinery Explosion was a classic disaster. A series of engineering and communication mistakes led to a 170-foot separation tower in the ISOM unit being overfilled with tens of thousands of gallons of extremely flammable liquid raffinate – the component of gasoline that really gives it a kick. The unit was designed to operate with about 6,000 gallons of liquid raffinate so once the vessel was completely filled, 52,000 gallons of 200 °F raffinate rushed through various attached vapor systems. Hot raffinate spewed into the air in a 20 foot geyser. With a truck idling nearby, an explosion was immanent.
This video from the US Chemical Safety Board (CSB) is easy to consume and well done. The 9 minutes starting at 3:21 explain the Texas City incident in detail:
I’ve studied this and other disasters in detail because in order to prevent disasters we have to understand their anatomy.
The Trigger
The trigger is the most direct cause of a disaster and is usually pretty easy to identify. The spark that ignited the explosion. The iceberg that ruptured the ship’s hull. The levee breaches that flooded 80% of New Orleans.
But the trigger typically only tells a small part of the story and it usually generates more questions than answers: Why was there a spark? Why was highly flammable raffinate spewing everywhere? Why was there so much? What brought these explosive ingredients together after so many people had worked so hard to prevent situations exactly like this?
While the trigger is a critical piece of the puzzle, a thorough analysis of a disaster has to look at the bigger picture.
When The Stars Align
The word disaster describes rapidly occurring damage or destruction of natural or man-made origins. But the word disaster has its roots in the Italian word disastro, meaning “ill-starred” (dis + astro). The sentiment is that the positioning of the stars and planets is astrologically unfavorable.
One of the things I learned from pouring over the incident reports of the Texas City Explosion was that disasters tend to only happen when at least 3 or 4 mistakes are made back to back or simultaneously – when the stars align.
Complex systems typically account for obvious mistakes. But they less frequently account for several mistakes occurring simultaneously. The stars certainly aligned in the case of the Texas City Refinery Explosion:
Employees and contractors were located in fragile wooden portable trailers near dangerous units that were about to start up.
The start-up process for the ISOM unit began just after 2 AM, when workers were tired and conditions were not ideal.
The start-up was done over an 11 hour period meaning that the procedure spanned a shift change – creating many opportunities for miscommunication. Unfortunately, the start-up could have easily been done during a single shift.
At least one operator had worked 30 back to back 12 hour days because of the various turnaround activities at the refinery and BP’s cost-cutting measures.
One liquid level indicator on the vessel that was being filled was only designed to work between a certain narrow range.
Once the unit was filled above the indicator’s upper range, the indicator reports incorrect values near the upper range, misleading operators regarding the true conditions of the liquid level. (ie: at one point the level indicator would report that the liquid levels in the tower were only at 7.9 feet when they were actually over 150 ft)
A backup high level alarm located above the level indicator failed to go off.
The lead operator left the refinery an hour before his shift ended.
Operators did not leave adequate or clear logs for one another meaning that knowledge failed to transfer between key players.
The day shift supervisor arrived an hour late for his shift and therefore missed any opportunity for direct knowledge transfer.
Start-up procedures were not followed and the tower was intentionally filled above the prescribed start-up level because doing so made subsequent steps more convenient for operators.
The valve to let fluids out of the tower was not opened at the correct time even though the unit continued to be filled.
The day shift supervisor left the refinery due to a family emergency and no qualified supervisor was present for the remainder of the unfolding disaster. A single operator was now operating all 3 units in a remote control center, including the ISOM unit that needed special attention during start-up.
Operators tried various things to reduce the pressure at the top of the tower without understanding the circumstances in the tower. One of the things they tried – opening the valve that moved liquids from the bottom of the tower into storage tanks (a step that they had failed to do hours earlier) – caused very hot liquid from the tower to pass through a heat exchanger with the fluid entering the tower. This caused the temperature of the fluid entering the tower to spike, exacerbating the problems even further.
The tower, which was never designed to be filled with more than a few feet of liquid, had now been filled to the very top – 170 feet. With no other place to go, liquid rushed into the vapor systems at the top of the tower.
At this point, no one knew that the tower had been overfilled with boiling raffinate. The liquid level indicator read that the unit was only filled to 7.9 feet.
Over the next 6 minutes, 52,000 gallons of nearly boiling, extremely flammable raffinate rushed out of the top of the unit and into adjacent systems – systems that were only designed to handle vapors, not liquids.
Thousands of gallons of raffinate entered an antiquated system that vents hydrocarbon vapors directly to the atmosphere – called a blowdown drum.
A final alarm – the high level alarm on the blowdown drum – failed to go off. But it was too late. Disaster was already immanent.
Raffinate spewed from the top of the blowdown drum. The geyser was 3 feet wide and 20 feet tall. The hot raffinate instantly began to vaporize, turning into a huge flammable cloud.
A truck, idling nearby, was the ignition source.
The portable trailers were destroyed instantly by the blast wave and most of the people inside were killed. Fires raged for hours, delaying rescue efforts.
Man-made disasters don’t just happen in complex systems. The stars have to align. But the quality of the mistakes matters a lot. Had even one key error above been avoided or caught, this incident wouldn’t have happened. In this case, overfilling the unit by 150,000 gallons of nearly boiling flammable raffinate, set off a chain of events that guaranteed disaster.
The Snowball Effect
Not all mistakes are made equally. Several of the errors in the Texas City Refinery Explosion compounded: Had operators followed the start-up procedure and not filled the tower beyond the designed level, had the tower been better designed to communicate liquid levels over a broader range, had the valve draining the tower been opened at the correct time, had the operators communicated properly between shifts… Had any one of these mistakes been avoided, the tower wouldn’t have been over filled and this disaster would have been prevented.
Miscommunication errors seem to have a special way of compounding and spiraling out of control.
While preventing some of the other mistakes might have mitigated the damage done, failing to understand the quantity of raffinate in the tower ultimately caused the disaster at Texas City.
Preventing Disasters
Think about the complex systems you care about in your business and life. List the raw ingredients for a disaster. What information do decision makers and operators need in order to react appropriately?
Identify the singular points of failure and the obvious triggers. Brainstorm scenarios – both common and uncommon – in order to better understand how different mistakes could interact with one another and how they could snowball out of control.
Pay attention to both the system’s design and the human errors – especially communication errors – that will inevitably arise during normal operation. Think about how you can design the system to be more resilient without sacrificing too much efficiency. What brakes can you build into the process to slow down snowballs?
Where do you need warning alarms? What are the right set-points for each alarm? How vocal do the alarms need to be? What happens when the alarms fail? How often will you test or double check your alarms?
Summary
Disasters tend to happen within large and complex systems. Usually, the immediate cause of a disaster – the literal or figurative spark or trigger – can be readily identified. But there’s almost always a bigger picture, a series of mistakes and errors that led to that spark or gave that spark power. Some of those mistakes set off bigger and bigger problems, which can snowball into something truly catastrophic.
Bottom Line: Understanding the anatomy of a disaster in your world is the first step to designing better systems, procedures, and training to help mitigate damage or prevent disasters altogether.