It’s Monday, March 19, 2018 and today we’re talking about: Toys”R”Us to Liquidate All US & UK Assets, the Concept of Category Killers, Putin Preserving Power, and Dropbox to IPO on Friday.
Toys”R”Us Liquidation
Toys”R”Us filed to liquidateall of its US and UK assets last week after filing for bankruptcy last September. The 70-year-old retail toy store has 875 stores in North America, 100 stores in the UK, and 64,000 employees.
I was a Toys”R”Us Kid. My parents never took me there or bought me toys, but I sure loved their commercials growing up. I can hear the jingle now. But what happened to all of those happy snaggletoothed 80’s and 90’s kids with their beloved over-priced plastic? Apparently they grew up, had kids themselves, and then didn’t take them to Toys”R”Us either.
Customers have been choosing Walmart, Target, and Amazon over the past few decades, systematically demolishing several brick and mortar retail sectors: records, books, consumer electronics, office supplies, and now toys. That’s Tower Records (defunct), Virgin Records (defunct), Barnes & Noble (Feb 2018: layoffs), Borders (defunct), Best Buy (March 2018: shutting down 250 Best Buy Mobile stores), Staples (March 2014: closing 225 stores), and OfficeMax (May 2014: closing 400 stores).
Now, my childhood dream of simply stepping foot inside of a Toys”R”Us is crumbling before my eyes. It seems likely that all 1600 stores world wide will be closed, franchised, or liquidated. And I predict that any franchises will be doomed from the start without the ongoing support of the corporate brand.
I guess we’re all Amazon kids now..
Category Killers
Like the top dogs of each of the other industries above, Toys”R”Us was considered a “category killer.” Category Killers are deep specialists in a sector who leverage their narrow focus to gain a competitive edge over less focused firms through increased bargaining power, pricing tactics, large selection, and strong branding.
Vladimir Putin was re-elected Sunday as President of Russia for another 6 year term. He has been either President or Prime Minister of Russia since 1999 when Boris Yeltsin resigned and choose Putin as his successor.
It’s widely believed that – despite Putin’s popularity in Russia – the results are not what they seem. The 67.5% turnout is suspiciously high and reports of ballot-box stuffing and forced voting have already surfaced.
Alexei Navalny, Putin’s biggest political opponent, was barred from even running in the election after being convicted of embezzlement. The charges are believed to be politically motivated and retaliation for Navalny’s anti-corruption campaigns. The 7 other candidates in the race appealed only to niche populations and had no serious hopes of winning the election.
And while term limits (of 2 consecutive 6-year terms) prevent him from running for President again in 2024, Putin can just “sit out” for a term as Prime Minister – exactly like he did in 2008. Assuring that one of his puppets would become President and allow him to govern from the Prime Minister’s seat was easy in 2008 and could be just as easy in 2024.
But regardless of interference allegations, Putin was already assured victory before the election. I mean, he only held one campaign event. So why interfere with a race you’re supposed to win?
Mandate. Putin and his allies can now point to a 67.5% voter turnout and a 76.6% victory as a mandate from the Russian people to rule however he sees fit. Keep an eye out for new policies and announcements as Putin enters his 2nd “lame duck” term.
Putin consistently proves that in order to maintain power you must get the right pieces to the right place at the right time. Being secretive and covert is a nice-to-have.
Dropbox IPO
Dropbox is poised to IPO this Friday. Offering shares at a price of $16-18, the cloud-storage company is attempting to raise up to $650 million. On the high end, the company would be valued at $7.1 billion – 30% lower than it’s peak in 2014.
While I like Dropbox and am one of the 11 million paying customers (of 500 million), the competition is fierce in the cloud storage market and the company has really struggled to clearly differentiate itself from competitors and launch other high-value services for small and medium size businesses.
To me, Dropbox is yet another case of Silicon Valley Hot Potato… it’s fun to get your hands on stock for a bit, but if you want to make money after the first few rounds, you’d better not be left holding it when the music stops. The question for current and would-be investors is: Has the music already stopped?
Our usual institutions let us pretend to be trying to get the thing we pretend to want while actually – under the surface – giving us the things we actually want.
Policy analysts typically try to analyze how to give policy reforms that would give us more of the things we pretend to want. And we’re usually uninterested in that because we know we don’t actually want more of the things we pretend we want.
If you could design a policy reform that let us continue to pretend to get the things we pretend to want while actually getting more of the things we actually want, we’d like that. But we can’t admit it. If we stumble into it, we’ll stay there.
But if the policy analysts were just to out loud say “Well this is a system that will give you more of this thing that’s what you actually want. But admit it.” We don’t want to admit it. And then we won’t want to embrace that.
So yes, what we want to do is pay for the appearance of the thing we’re pretending to want and we’re often paying a lot for that appearance.
– Robin Hanson
The Elephant in the Brain: Hidden Motives
Great quote from Robin Hanson about how we’re often not honest with ourselves about our hidden motives and what that means for our policies regarding education, guns, healthcare, immigration, inequality, capitalism, and corporatism.
Hanson’s accessible book focuses on motives and norms but also covers selfishness, hypocrisy, norm violation, cheating, deception, self-deception, signaling, counter-signaling, social status (separated into dominance and prestige), power, money, and loyalty.
My 3 biggest takeaways from Hanson’s conversation with Harris were:
How frequently we are dishonest with ourselves about our motives
When it comes to what people want, you’re better off watching their actions than taking their word
It’s okay to be agnostic on things you haven’t looked into deeply – you’ll probably be happier too.
Why don’t we learn from past experiences when it comes to planning new projects? Why aren’t even our best laid plans realistic?
Surely you’ve noticed this – whether it’s getting your taxes done, that big presentation for work, or planning your wedding.
Why do 80-90% of mega projects run over budget and over schedule?
Why has it taken – for example – nearly 100 years to expand the Second Avenue Subway in NYC? The original project was expected to cost 1.4 billion dollars (a 1929 estimate in 2017 dollars) and now with Phase 1 completed ($4.5 billion to build just 3 of the 16 proposed stations), Phase 2 is expected to cost $6 billion.
This phenomenon has been dubbed The Planning Fallacy – the topic of today’s Freakonomics podcast and the inspiration for this post.
Don’t have 45 minutes to listen? Keep reading.
Why do we fall for The Planning Fallacy again and again?
When planning a project we naturally focus on the case at hand, building a simulation in our minds. But our simulations are rosy, idealized, and don’t account for all of the complexities that will inevitably unfold.
We also focus on succeeding, not failing, creating an optimism bias. This means we don’t think enough about all the things that can go wrong.
We’re overly confident, believing in our abilities and the old “this time will be different“ line too much.
We ignore the complexity of integrating all of the parts of a project together.
We intentionally misrepresent a project’s plans in order to get it approved.
We rely too heavily on our subjective judgement instead of the facts and past empirical data.
And of course: incompetence, fraud, deliberate deception, cheating, stealing, and politicking.
Use past projects – even if they’re not exactly comparable – as a benchmark for projects being planned.
Track and score the difference between forecasts and outcomes.
Get stakeholders to put skin in the game, creating rewards and penalties for good and bad performance. #IncentivesMatter.
Use data and algorithms to reduce human biases.
Use good tools to help you focus. Asana co-founder Justin Rosenstein warns against “continuous partial attention” – a state of never fully focusing on any one thing.
Success Building Software
I build projects for a living – mostly product strategy and software for start-ups or innovation groups within larger companies. I plan and execute on projects everyday and I still struggle with the planning fallacy in other areas of my business (did I mention my corporate taxes are due in 7 days?).
But the secret sauce to my successes building products has always been to 1) have personal expertise in what’s being planned and built, 2) refine and go over the plans until your eye bleed looking for possible pitfalls, and 3) have a clear and easy-to-follow process to keep you focused on the right thing at the right time.
Terms & Concepts
The Planning Fallacy – Poorly estimating the timeline, quality, and budget of a planned project while knowing that similar projects have taken longer, cost more, or had sub-par results.
The Optimism Bias – Focusing on the positives of a situation over the negatives.
Overconfidence – Thinking that we’ll perform better than we actually will.
Coordination Neglect – Failing to account for how difficult it is to coordinate efforts and combine all of the individual outputs into one complete system.
Procrastination – Choosing to do things that we enjoy in the short term instead of the things we think will make us better further down the road. In the episode, Katherine Milkman called procrastination a “self-control failure” – my new favorite phrase.
Reference Class Forecasting – Using past and similar projects as a benchmark for how your next project will perform.
Strategic Misrepresentation – Underestimating the costs and over representing the benefits of a project.
Algorithm Aversion – The big thing that Katy Milkman thinks is holding us back from using “data instead of human judgement to make forecasts” better.
When I first started working at the nation’s largest refinery my boss didn’t have any great projects ready for me so he sent me to “Shift Super” training. There were only 4 of us students – me and 3 unit operators, each with at least 20 years of experience. I was only 19 years old and I barely knew anything about anything.
Each shift supervisor runs a big chunk of the refinery: 2-4 major units. But shift supers needed to know how to supervise any of the 10 or so control centers safely, so on my first day of work I was learning how the entire refinery operated. It felt like a lifetime’s education crammed into 5 days.
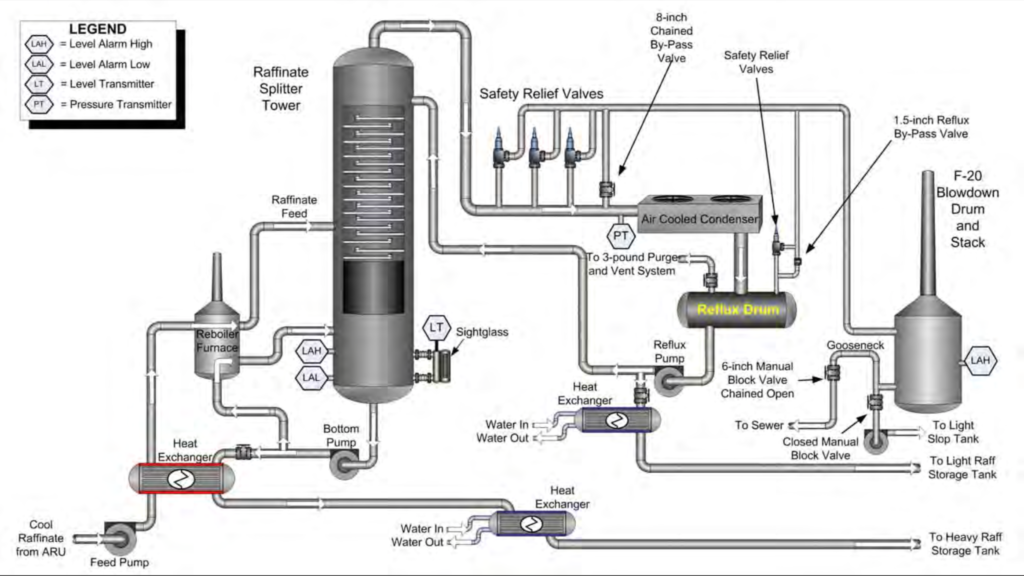
After Shift Super training, I began to see more and more of the refinery with my own eyes. What had been a precise line drawn from one perfect cylinder to another perfect cylinder was actually a rust covered 6-inch pipe baking in the Texas heat transporting high-octane, extremely flammable raffinate from a 170 ft separation tower to a temporary holding tank.
Fear of Disaster
One evening – about 2 weeks in – as the refinery was becoming a real place to me, I had this moment of pure panic while driving home.
With so many things that could go wrong at any moment, how was the refinery still standing? How had it even made it until now? Any minor mistake – in the design, production, construction, or operation of any pipe or vessel – could result in a huge disaster. Would the refinery even be there when I returned tomorrow morning?
I couldn’t sleep. The next morning the refinery was still there. And the next. And the next. And my fears slowly morphed into amazement. My refinery was the largest, most complicated system I had ever attempted to wrap my brain around.
BP Texas City Refinery Explosion
But just 29 miles away from my refinery, investigators were trying to piece together what happened during the nation’s worst industrial disaster in nearly 2 decades.
Fifteen people had been killed and 180 injured – dozens were very seriously injured. The cause of each fatality was the same: blunt force trauma.
Windows on houses and businesses were shattered three-quarters of a mile away and 43,000 people were asked to remain indoors while fires burned for hours. 200,000 square feet of the refinery was scorched. Units, tanks, pipes were destroyed and the total financial loss was over $1.5 billion.
The BP Texas City Refinery Explosion was a classic disaster. A series of engineering and communication mistakes led to a 170-foot separation tower in the ISOM unit being overfilled with tens of thousands of gallons of extremely flammable liquid raffinate – the component of gasoline that really gives it a kick. The unit was designed to operate with about 6,000 gallons of liquid raffinate so once the vessel was completely filled, 52,000 gallons of 200 °F raffinate rushed through various attached vapor systems. Hot raffinate spewed into the air in a 20 foot geyser. With a truck idling nearby, an explosion was immanent.
This video from the US Chemical Safety Board (CSB) is easy to consume and well done. The 9 minutes starting at 3:21 explain the Texas City incident in detail:
I’ve studied this and other disasters in detail because in order to prevent disasters we have to understand their anatomy.
The Trigger
The trigger is the most direct cause of a disaster and is usually pretty easy to identify. The spark that ignited the explosion. The iceberg that ruptured the ship’s hull. The levee breaches that flooded 80% of New Orleans.
But the trigger typically only tells a small part of the story and it usually generates more questions than answers: Why was there a spark? Why was highly flammable raffinate spewing everywhere? Why was there so much? What brought these explosive ingredients together after so many people had worked so hard to prevent situations exactly like this?
While the trigger is a critical piece of the puzzle, a thorough analysis of a disaster has to look at the bigger picture.
When The Stars Align
The word disaster describes rapidly occurring damage or destruction of natural or man-made origins. But the word disaster has its roots in the Italian word disastro, meaning “ill-starred” (dis + astro). The sentiment is that the positioning of the stars and planets is astrologically unfavorable.
One of the things I learned from pouring over the incident reports of the Texas City Explosion was that disasters tend to only happen when at least 3 or 4 mistakes are made back to back or simultaneously – when the stars align.
Complex systems typically account for obvious mistakes. But they less frequently account for several mistakes occurring simultaneously. The stars certainly aligned in the case of the Texas City Refinery Explosion:
Employees and contractors were located in fragile wooden portable trailers near dangerous units that were about to start up.
The start-up process for the ISOM unit began just after 2 AM, when workers were tired and conditions were not ideal.
The start-up was done over an 11 hour period meaning that the procedure spanned a shift change – creating many opportunities for miscommunication. Unfortunately, the start-up could have easily been done during a single shift.
At least one operator had worked 30 back to back 12 hour days because of the various turnaround activities at the refinery and BP’s cost-cutting measures.
One liquid level indicator on the vessel that was being filled was only designed to work between a certain narrow range.
Once the unit was filled above the indicator’s upper range, the indicator reports incorrect values near the upper range, misleading operators regarding the true conditions of the liquid level. (ie: at one point the level indicator would report that the liquid levels in the tower were only at 7.9 feet when they were actually over 150 ft)
A backup high level alarm located above the level indicator failed to go off.
The lead operator left the refinery an hour before his shift ended.
Operators did not leave adequate or clear logs for one another meaning that knowledge failed to transfer between key players.
The day shift supervisor arrived an hour late for his shift and therefore missed any opportunity for direct knowledge transfer.
Start-up procedures were not followed and the tower was intentionally filled above the prescribed start-up level because doing so made subsequent steps more convenient for operators.
The valve to let fluids out of the tower was not opened at the correct time even though the unit continued to be filled.
The day shift supervisor left the refinery due to a family emergency and no qualified supervisor was present for the remainder of the unfolding disaster. A single operator was now operating all 3 units in a remote control center, including the ISOM unit that needed special attention during start-up.
Operators tried various things to reduce the pressure at the top of the tower without understanding the circumstances in the tower. One of the things they tried – opening the valve that moved liquids from the bottom of the tower into storage tanks (a step that they had failed to do hours earlier) – caused very hot liquid from the tower to pass through a heat exchanger with the fluid entering the tower. This caused the temperature of the fluid entering the tower to spike, exacerbating the problems even further.
The tower, which was never designed to be filled with more than a few feet of liquid, had now been filled to the very top – 170 feet. With no other place to go, liquid rushed into the vapor systems at the top of the tower.
At this point, no one knew that the tower had been overfilled with boiling raffinate. The liquid level indicator read that the unit was only filled to 7.9 feet.
Over the next 6 minutes, 52,000 gallons of nearly boiling, extremely flammable raffinate rushed out of the top of the unit and into adjacent systems – systems that were only designed to handle vapors, not liquids.
Thousands of gallons of raffinate entered an antiquated system that vents hydrocarbon vapors directly to the atmosphere – called a blowdown drum.
A final alarm – the high level alarm on the blowdown drum – failed to go off. But it was too late. Disaster was already immanent.
Raffinate spewed from the top of the blowdown drum. The geyser was 3 feet wide and 20 feet tall. The hot raffinate instantly began to vaporize, turning into a huge flammable cloud.
A truck, idling nearby, was the ignition source.
The portable trailers were destroyed instantly by the blast wave and most of the people inside were killed. Fires raged for hours, delaying rescue efforts.
Man-made disasters don’t just happen in complex systems. The stars have to align. But the quality of the mistakes matters a lot. Had even one key error above been avoided or caught, this incident wouldn’t have happened. In this case, overfilling the unit by 150,000 gallons of nearly boiling flammable raffinate, set off a chain of events that guaranteed disaster.
The Snowball Effect
Not all mistakes are made equally. Several of the errors in the Texas City Refinery Explosion compounded: Had operators followed the start-up procedure and not filled the tower beyond the designed level, had the tower been better designed to communicate liquid levels over a broader range, had the valve draining the tower been opened at the correct time, had the operators communicated properly between shifts… Had any one of these mistakes been avoided, the tower wouldn’t have been over filled and this disaster would have been prevented.
Miscommunication errors seem to have a special way of compounding and spiraling out of control.
While preventing some of the other mistakes might have mitigated the damage done, failing to understand the quantity of raffinate in the tower ultimately caused the disaster at Texas City.
Preventing Disasters
Think about the complex systems you care about in your business and life. List the raw ingredients for a disaster. What information do decision makers and operators need in order to react appropriately?
Identify the singular points of failure and the obvious triggers. Brainstorm scenarios – both common and uncommon – in order to better understand how different mistakes could interact with one another and how they could snowball out of control.
Pay attention to both the system’s design and the human errors – especially communication errors – that will inevitably arise during normal operation. Think about how you can design the system to be more resilient without sacrificing too much efficiency. What brakes can you build into the process to slow down snowballs?
Where do you need warning alarms? What are the right set-points for each alarm? How vocal do the alarms need to be? What happens when the alarms fail? How often will you test or double check your alarms?
Summary
Disasters tend to happen within large and complex systems. Usually, the immediate cause of a disaster – the literal or figurative spark or trigger – can be readily identified. But there’s almost always a bigger picture, a series of mistakes and errors that led to that spark or gave that spark power. Some of those mistakes set off bigger and bigger problems, which can snowball into something truly catastrophic.
Bottom Line: Understanding the anatomy of a disaster in your world is the first step to designing better systems, procedures, and training to help mitigate damage or prevent disasters altogether.
“At the opening of the 2002 season, the richest [baseball] team, the New York Yankees, had a payroll of $126 million while the two poorest teams, the Oakland A’s and the Tampa Bay Devil Rays, had payrolls of less than a third of that, about $40 million.”
For the Oakland A’s the exact number was $41,942,665. Oakland won 103 games that regular season, while the Texas Rangers had only won 72 and spent $106,915,180. This phenomena was somewhat common actually. Many of the richest teams in Major League Baseball were not delivering results while the Oakland A’s were… consistently.
Let’s look at this another way. Teams have to spend a minimum of $7 million on payroll and a team that’s spending the minimum payroll is expected to win about 49 games during the 162 game season. So, on a dollar-per(-marginal)-win basis the A’s were spending about $650,000 per win while Texas was spending about $4.3 million for each win. What explains this nearly 7x delta in ROI?
The two word answer is simple: Bad Tactics.
Traditional Tactics
Baseball is a sport steeped in tradition and the decade preceding the 2002 season saw teams payrolls rise by tens of millions of dollars per team, up to a 400% increase. These new costs meant that more people were paying attention to how effectively this money was being spent.
In 2002, the vast majority of MLB scouts were still judging players by whether they had a “good face” and by the 5 Tools – running, throwing, fielding, hitting, and hitting power. These subjective metrics were used in place of the enormous data sets that baseball had been collecting since the invention of the box score in 1845.
The data was clear. In 2002, RBIs (runs batted in), stealing bases, bunts, batting average, slugging, foot speed, high school players (vs college), and old (vs new/fresh) pitching arms were all tremendously over-valued in players – and it showed in their salaries.
The following were underpriced: High pitches per at-bat – which wore down pitchers – walks, and any other activity that got a hitter on base instead of out. So despite the availability of the data, the statistics to make sense of it, and the computing power to crunch the numbers, looks and luck were still being priced over results.
The human mind played tricks on itself when it relied exclusively on what it saw, and every trick it played was a financial opportunity for someone who saw through the illusion to the reality.
Baseball teams simply insisted on using bad tactics – which of course amounts to bad strategy. But reliance on knowably bad tactics happen outside of baseball too.
Insider vs Outsider CEOs
A recent episode of the Freakonomics podcast (How to Become a C.E.O.) illustrates another example of reliance on subjective decision making when good, relevant data is available:
A 2009 academic study, which analyzed established public companies from 1986 to 2005, found that internally promoted C.E.O.’s led to at least a 25 percent better total financial performance than external hires.” A 2010 study by Booz & Company similarly found that, in 7 of the 10 previous years, insider C.E.O.s delivered higher market returns than external hires. And yet: external hiring seems to be on the rise: in 2013, between 20 and 30 percent of boards replaced outgoing C.E.O.’s with external hires; a few decades ago, that number was only 8 to 10 percent. Outside hires also tend to be more expensive: their median pay is $3 million more than for inside hires. So, an external hire will, on average, cost you more and perform worse. And yet that’s the trend.
Overpay & Underdeliver
Why do companies overpay for inferior results? Why do baseball teams?
I think the biggest reasons is fear. The fear of humiliation and failure drove both baseball management and corporate boards into the bad tactics of over-paying for inferior results. When you focus on avoiding failure instead of finding success, you’re less likely to see new opportunities and adapt.
There’s also an issue of misaligned incentives at work too. In baseball, owners and managers care more about not being embarrassed by their performance than about wins. A losing team can still be profitable and have a great return. In the business world, board members and CEOs are often scratching one another’s backs and giving one another high paying jobs instead of focused on increasing shareholder value.
And, of course, it’s not always clear who’s delivering value, who’s slacking, or who’s just getting lucky or unlucky – in both a corporate environment and on the baseball diamond.
Recognizing Bad Tactics
So how do you recognize bad tactics?
1) Define what’s important to you.
For boards, they want CEOs who will deliver returns for a fair price. For baseball teams, regular season wins are the key to having a shot at the world series.
2) Look at the data & try to understand how different actions affect the outcomes you care about.
If there’s no data or bad data, start investing in this area. Try to put a value on different skills or results (on-base percentage, walks, or market-cap). How are different variables connected? What’s currently undervalued and what’s overvalued?
3) Ask hard, even contrarian, questions and seek out different perspectives.
Challenge the norms within your sector, culture, or league. Don’t be different just to be different but understand that the standard approach – or even your entire industry – might be severely under-optimized. Seeing reality through the illusion is incredibly valuable.
4) Be honest with yourself.
Embrace your findings. Act on them. Yes, that probably means risking failure.
Moneyball
I was inspired to write this post after reading Michael Lewis’ Moneyball. While I haven’t been a baseball fan since I was about 9 years old, listening to Bill James (one of the key players in all of this) on Russ Robert’s EconTalk got me really excited about the story of the Oakland A’s 2002 season – which was made into a very popular movie as well. I highly recommend readingMoneyball – which uses baseball as an analogy for the tactical and strategic failings of many organizations.